一、业务背景
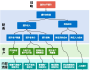
1.1 数据建模现状:互联网企业往往存在多个产品线,每天源源不断产出大量数据,这些数据服务于数据分析师、业务上的产品经理、运营、数据开发人员等各角色。为了满足这些角色的各种需求,业界传统数仓常采用的是经典分层模型的数仓架构,从ODS>DWD>DWS>ADS逐层建模,重点支持BI分析,如下图:

1.2 当前业务特性与趋势互联网产品快速迭代,业务发展越来越快,跨业务分析越来越多,数据驱动业务越来越重要。 数据服务的主要群体正在从数据研发转向产品人员,使用门槛需要进一步降低。 二、面临的问题
2.1 在数据驱动业务越来越重要的大趋势下,面临的问题面临着如下问题,如下图:

2.2 思考那么在生产实践中如何解决上述面临的问题及痛点呢,在对业务线进行调研和对具体用户访谈后,根据调研和访谈结论,得出以下想法: 1)节约数仓整体存储,数仓不分层,用更少的表满足业务需求,比如一个主题一张宽表; 2)明确数据表使用方式,确保口径清晰统一,避免业务方线下拉会沟通,降低沟通成本,提高沟通效率; 3)加速数据查询,快速满足业务需求,助力数据驱动业务。 三、技术方案根据上述的想法,经过可行性分析后,提出一层大宽表模型替代经典数仓维度模型的技术方案,来解决数仓存储大量冗余、表多且口径不清晰和查询性能低的问题。 3.1 大宽表模型替代经典数仓维度模型
3.1.1 大宽表模型架构用一层大宽表在数仓层内替换使用维度模型建的表,在数仓层间替换传统的ODS>DWD>DWS>ADS逐层建模的分层架构,最终报表和adhoc场景可直接使用大宽表,如下图:

3.1.2 大宽表建设方案根据产品功能和业务场景的不同,把日志分为不同主题,在各个主题内按各个业务使用的细节程度和业务含义进行宽表建设,建设时统一ods层与dwd层的表粒度,覆盖下游业务所有字段需求,包含明细表所有字段,也覆盖各层的维度字段及指标列,用来满足上层的业务指标分析等各种需求,主要支持报表分析和adhoc场景查询,具体如下图:

3.1.3 大宽表建设原理1)采用Parquet列式存储,可支持宽表数百列,超多字段,再经过按列的高效压缩和编码技术,降低了数仓整体存储空间,提高了IO效率,起到了降低上层应用延迟的效果 2)将各层之间的事实表复杂嵌套字段打平后与各个维度表、指标等进行join生成宽表,宽表的列最终分为公共属性、业务维度属性和指标属性 3.1.4 宽表优点及性能1)一层大宽表替换维度模型,通过极少的冗余,做到了表更少,口径更清晰,同时业务使用上更方便,沟通更流畅,效率更高在同一主题内,建设宽表时将维度表join到事实表中后,事实表列变多,原以为会增加一些存储,结果经过列式存储中按列的高效压缩和编码技术,降低了存储空间,在生产实践场景中,发现存储增加极少。替换后在数仓层内只有一张宽表,且表结构清晰明了,使得沟通效率大大提升,如下图:

2)经典数仓层与层存在大量冗余,一层大宽表替换多层数仓,数仓总存储下降 30% 左右,节约了大量存储 经典数仓架构中,同一主题在数仓间存在大量冗余存储,比如业务上经常从ODS层抽取字段生成DWD层数据,抽取的字段在这两层间就会出现大量冗余,同理,主题内其他层与层之间也存在大量冗余。在同一主题内按业务使用的细节程度和具体业务含义,将表粒度精简后统一成一个粒度,按该粒度并包含下游业务所需字段,生成宽表,可避免数仓层间的大量冗余。也就是整个数仓无需分层,只有一层大宽表,一个主题有一到两个宽表。在生产实践中建设大宽表后,数仓总存储下降30%左右,大大节约了存储成本,如下图:

3)性能对比 到这里可能会有疑问,宽表数据量既然变多了,在查询上会不会有性能损失呢? 可分为三类场景: 场景1:经典数仓表和一层宽表存储相近的情况下,宽表使用了列式存储和统计滤波,简单查询,尤其是简单聚合查询会更快 场景2:依然是经典数仓表和一层宽表存储相近的情况下,经典数仓中需要使用explode等函数进行的复杂计算场景,在宽表中绝大部分需求通过count、sum即可完成,因为宽表会将业务指标下沉,复杂字段拆分打平,虽然行数变多了,但避免了explode,get_json_object等耗时操作,查询性能极高 场景3:经典数仓表和一层宽表存储相差较大的情况下,宽表性能有一定的损失,但在业务接受范围内,影响不大,如下图: 3.1.5 宽表带来的挑战宽表建模在提升数据易用性及查询性能的同时,也带来了一些挑战: 1) 开发成本:宽表为了尽可能多的满足业务需求,封装了大量的ETL处理逻辑及关联计算,这会使宽表代码更加复杂,开发迭代维护成本更高。 2) 回溯成本:在业务迭代过程中,往往伴随着指标口径的升级、日志打点的变动,需要宽表回溯历史数据。而宽表本身数据量较大,计算逻辑复杂,回溯时会额外消耗较多的计算资源,存在较高的回溯成本。 3) 产出时效:由于宽表本身上游数据源多、数据量大,当多个上游数据就绪时间不尽相同时,宽表的产出时效会出现木桶效应。 针对以上,结合实际应用我们探索了一些解决思路: 开发成本增加,主要原因是宽表进行了更多的ETL操作和封装了更多的指标口径计算,这本质上其实是研发成本和使用成本之间的权衡,将一部分下游用户使用时再计算的成本提前封装到宽表中。而如果宽表的下游用户越多,这种研发成本的提升对整体业务成本实际上是下降的,也就是我们说的降低使用门槛、提升自助化率。因此在当前数据分析平民化的背景下,实际总成本是下降的。 回溯成本的增加,体现在原来只需回溯一个dws或ads层的小表,现在可能要回溯整张宽表。这里在实际生产中,我们在技术上可以探索一些优化方案,包括: (1)将宽表设置不同的业务分区,回溯时只更新对应的分区数据; (2)基于宽表作为输入,回溯所需字段,避免重新执行生成宽表的复杂计算逻辑; (3)利用在线服务夜间空余的潮汐资源,进一步降低回溯资源开销。 上游多个数据源产出时效不同步的问题,这里可以考虑2种方式: (1)通过上游数据流批一体化改造,提升上游数据时效性 (2)当上游数据无法提速时,可以考虑分批产出不同分区的数据,这种方式需要meta系统和调度系统同步支持,会提升系统复杂度。 四、总结与规划1)宽表建模更适合面向快速迭代的数据驱动型业务,能够提升业务效率 2)基于当前的业务实践,宽表在存储和查询性能方面相比于传统数仓更优 3)在业务效率提升的同时,宽表的建设会对数据生产和维护成本有所提升,还需结合实际应用进一步优化探索 未来规划:基于宽表可以更方便的构建自助分析平台,进一步提升业务分析效率。
(以上内容摘录自网络,如有侵权请联系删除)
|