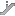|
世界人工智能大会刚刚结束,大家的一个共识就是做大模型应用。作为一名数据工作者,自己也一直在进行大模型应用的探索,下图列出的是我认为在数据领域具备潜力的十大价值应用: 针对每个应用,我对其可落地性进行了评估,如下所示,五星代表非常靠谱,一星代表离实用还有距离。
▪ 数据清洗和标准化:★★★★★ (5星)
▪ 自然语言查询接口:★★★☆☆ (3星)
▪ 数据分析和洞察生成:★★☆☆☆ (2星)
▪ 元数据管理和数据目录增强:★★★★☆ (4星)
▪ 数据隐私和匿名化:★★★★☆ (4星)
▪ 智能数据集成:★★☆☆☆ (2星)
▪ 自动化数据文档生成:★★★☆☆ (3星)
▪ 智能数据建模:★★☆☆☆ (2星)
▪ 数据合规性检查:★★★☆☆ (3星)
▪ 异常检测和数据质量监控:★☆☆☆☆ (1星)下面,会对每个应用进行详细介绍,包括推荐的理由,详细的案例,希望带给您新的启示。
1、数据清洗和标准化 理由:数据清洗和标准化是一个高度重复性的任务,LLM能够理解多种数据格式和上下文,可以高效地执行这类任务。随着企业非结构化数据使用场景的增加,且技术相对成熟,大模型在这方面的应用会井喷,但可能需要一些人工监督来确保准确性。 实用性:★★★★★ (5星) 例子: 假设一家电子商务公司从多个渠道收集了客户数据,导致数据格式不统一、存在错误和缺失。以下是LLM如何帮助清洗和标准化这些数据的详细过程: 原始数据样本:

LLM清洗和标准化过程: (1)姓名标准化: ▪ 统一使用中文姓名 ▪ 删除非法字符 ▪ 修正大小写 (2)电话号码格式化: ▪ 统一为13位数字格式(包括国家代码) ▪ 删除多余的字符(如破折号、空格) (3)邮箱验证和修正: ▪ 检查邮箱格式的有效性 ▪ 补全缺失的域名后缀 ▪ 将NULL值替换为待补充标记 (4)地址结构化: ▪ 统一地址格式(省市区街道) ▪ 添加缺失的邮政编码 ▪ 规范化小区名称和门牌号 (5)生日格式统一: ▪ 转换为YYYY-MM-DD格式 ▪ 对未知生日进行特殊标记 (6)最近购买日期标准化: ▪ 将相对时间转换为具体日期 ▪ 统一使用YYYY-MM-DD格式 清洗后的数据:

LLM执行的关键操作: ▪ 智能识别和纠正姓名:如将"WANG WU"更正为"王五"。 ▪ 统一电话号码格式:添加国家代码,删除分隔符。 ▪ 验证并修正电子邮箱:如为"lisi@email"添加".com"后缀。 ▪ 结构化和补全地址信息:如为上海地址添加"市"和邮编。 ▪ 标准化日期格式:将各种日期表示转换为YYYY-MM-DD格式。 ▪ 转换相对时间:如将"2周前"转换为具体日期(假设当前日期为2023-07-02)。 通过这个过程,LLM不仅执行了基本的数据清洗任务,还利用其语言理解能力处理了复杂的模糊情况,如解释相对日期、推断缺失信息等。这大大提高了数据质量,为后续的数据分析和应用奠定了基础。
2、自然语言查询接口 理由:LLM可以理解自然语言,将其转换为结构化查询语言,使非技术用户也能轻松查询复杂数据库,当前比较热的ChatSQL或者TxT2SQL都属于这个类别。虽然这个应用非常有前景,但准确性和安全性仍然是挑战。需要深度集成到现有数据系统中,极大受限于私有语料的完备度,可能需要大量定制化工作。 实用性:★★★☆☆ (3星) 例子: 假设一家全国连锁零售公司使用LLM构建了一个自然语言查询接口,允许非技术背景的管理人员直接用自然语言提问来分析销售数据。以下是一个详细的查询过程示例: 数据库结构简介: ▪ sales: 销售记录表 ▪ products: 产品信息表 ▪ stores: 门店信息表 ▪ customers: 客户信息表 用户查询: "去年第四季度销量最高的5种产品是什么?请按销量降序排列,并显示它们的总销售额和主要销售城市。" LLM处理过程: (1)理解查询意图: ▪ 时间范围: 去年第四季度 ▪ 查询对象: 产品 ▪ 排序标准: 销量降序 ▪ 限制数量: 前5种 ▪ 附加信息: 总销售额,主要销售城市 (2)识别需要的表和字段: ▪ sales: date, productid, quantity, totalamount ▪ products: productid, productname ▪ stores: store_id, city (3)构建SQL查询: sql WITH topproducts AS ( SELECT p.productid, p.productname, SUM(s.quantity) as totalquantity, SUM(s.totalamount) as totalsales, STRINGAGG(DISTINCT st.city, ', ' ORDER BY COUNT(*) DESC) as topcities FROM sales s JOIN products p ON s.productid = p.productid JOIN stores st ON s.storeid = st.storeid WHERE s.date BETWEEN '2023-10-01' AND '2023-12-31' -- 假设"去年"是2023年 GROUP BY p.productid, p.productname ) SELECT productname, totalquantity, totalsales, SUBSTRING(topcities, 1, CHARINDEX(',', topcities + ',') - 1) as maincity FROM topproducts ORDER BY totalquantity DESC LIMIT 5;
(4)执行查询并格式化结果 查询结果:
.png.png")
LLM生成的自然语言回复: "根据您的查询,以下是去年第四季度销量最高的5种产品,按销量降序排列: ▪ iPhone 13: 销量15,234台,总销售额7617万元,主要在北京热销。 ▪ AirPods Pro: 销量12,567个,总销售额1508万元,在上海最受欢迎。 ▪ Nintendo Switch: 售出10,891台,总销售额3267万元,广州是其最大市场。 ▪ iPad Air: 销量达9,876台,总销售额3950万元,深圳消费者对它情有独钟。 ▪ MacBook Air: 虽然销量排第五(8,765台),但总销售额最高,达到7889万元,主要在北京畅销。 值得注意的是,虽然MacBook Air的销量排名第五,但由于其较高的单价,总销售额反而是最高的。另外,我们可以看到,这些热销产品主要集中在一线城市如北京、上海、广州和深圳。 关键亮点: ▪ 复杂查询转换: LLM成功将一个包含多个条件和要求的自然语言查询转换为复杂的SQL语句。 ▪ 时间智能处理: 正确理解并转换"去年第四季度"这样的相对时间表述。 ▪ 数据聚合和排序: 实现了销量统计、金额汇总、城市聚合等复杂操作。 ▪ 结果智能呈现: 不仅提供了原始数据,还添加了洞察和观察。 ▪ 交互式体验: 在回答的基础上,主动提出了进一步分析的建议。 这个案例展示了LLM如何使复杂的数据分析变得具备可行性,即使对于没有SQL知识的用户也能轻松获取深入的业务洞察。
3、数据分析和洞察生成 理由:LLM可以分析大量数据,识别模式和趋势,并以易懂的自然语言形式呈现洞察,也是BI领域增强分析的未来。但这个应用的基础是ChatSQL,同时不仅理解数据,还要进行复杂的分析和推理,集成度和复杂度非常高。虽然潜力巨大,但目前的准确性和可靠性还不足以在关键业务决策中进行依赖。 实用性:★★☆☆☆ (2星) 例子: TechGrow是一家专注于提供企业软件解决方案的中型科技公司。公司成立5年,目前面临增长瓶颈,CEO要求对过去12个月的运营数据进行全面分析,以制定未来的增长策略。 数据概览: 分析基于以下数据: ▪ 销售数据: 包括每笔交易的日期、金额、产品、客户信息等 ▪ 产品数据: 包括产品类别、定价、开发成本、客户满意度评分等 ▪ 客户数据: 包括公司规模、行业、使用历史、支持请求等 ▪ 营销数据: 包括各渠道的支出、线索生成、转化率等
数据分析过程: LLM执行了以下分析步骤: (1)数据清洗和预处理 (2)描述性统计分析 (3)时间序列分析 (4)客户细分分析 (5)产品组合分析 (6)营销效果分析 (7)预测性分析 关键发现和洞察: (1)收入增长分析

洞察: ▪ 年度收入增长率为23%,但增长速度在逐月放缓。 ▪ Q4(10-12月)的收入增长最为显著,占全年增长的40%。 ▪ 收入增长曲线呈现出明显的阶梯式上升,可能与产品发布周期相关。 (2)客户细分分析

洞察: ▪ 企业客户贡献了50%的收入,但增长率最低(5%)。 ▪ 创业公司客户虽然只贡献20%的收入,但增长率最高(35%)。 ▪ 中小企业客户在收入贡献(30%)和增长率(15%)上表现均衡。 (3)产品组合分析

洞察: ▪ CRM系统是主打产品,贡献40%的收入,但满意度(4.2)低于平均水平。 ▪ 商业智能产品虽然收入占比最低(8%),但客户满意度最高(4.7)。 ▪ 人力资源管理系统在收入占比(25%)和满意度(4.5)上都表现良好。 (4)营销效果分析

洞察: ▪ 搜索引擎广告支出最高(30万美元),但ROI(250%)仅为中等水平。 ▪ 合作伙伴推荐计划支出最低(5万美元),但ROI最高(400%)。 ▪ 内容营销在适中的支出(15万美元)下取得了较高的ROI(300%)。 LLM提出以下战略建议: (1)客户策略: ▪ 加大对创业公司客户的营销和支持力度,aim提高其收入占比至25%。 ▪ 为企业客户开发增值服务和产品升级方案,目标提升增长率至10%。 ▪ 针对中小企业客户推出捆绑产品套餐,利用其Balance增长潜力。 (2)产品策略: ▪ 对CRM系统进行全面评估和优化,目标在6个月内将满意度提升至4.5。 ▪ 加大对商业智能产品的投入和推广,争取在下一财年将其收入占比翻倍。 ▪ 围绕人力资源管理系统建立生态系统,如开发第三方插件市场。 (3)营销策略: ▪ 将合作伙伴推荐计划的预算提高50%,扩大合作伙伴网络。 ▪ 优化搜索引擎广告策略,focus在高转化率的关键词上,目标将ROI提升至300%。 ▪ 增加内容营销投入,特别是针对创业公司和中小企业的教育性内容。 (4)增长策略: ▪ 实施季节性促销计划,尤其是在Q2和Q3,以平衡全年收入增长。 ▪ 探索新的地理市场,建议下一财年进入至少一个新的区域市场。 ▪ 开发基于AI的产品功能,提高产品竞争力和客户粘性。 LLM建议设立以下KPI来跟踪战略实施效果: ▪ 创业公司客户收入占比 ▪ 企业客户年增长率 ▪ CRM系统客户满意度评分 ▪ 商业智能产品收入占比 ▪ 合作伙伴推荐计划ROI ▪ 搜索引擎广告ROI ▪ Q2和Q3收入占全年比例 ▪ 新市场收入贡献 建议每月审查这些指标,每季度进行深入分析和必要的策略调整。同时,成立跨部门的"增长团队",负责协调和推进这些举措的实施。
4、元数据管理和数据目录增强 理由:LLM在理解和生成描述性信息方面表现出色,对准确度的容忍度高,非常适合这个任务。场景明确,实现难度相对较低。 实用性:★★★★☆ (4星) 例子: GlobalFinance 是一家跨国金融服务公司,拥有庞大而复杂的数据生态系统。公司面临以下挑战: ▪ 数据分散在多个系统和部门 ▪ 缺乏统一的数据定义和描述 ▪ 数据血缘关系不清晰 ▪ 数据使用效率低下 ▪ 难以确保数据合规性 为解决这些问题,公司决定实施一个基于大模型的智能元数据管理和数据目录系统。 实施过程: (1) 数据收集和整合 首先,大模型被用来扫描和解析公司的各种数据源,包括: ▪ 关系数据库 (Oracle, SQL Server, MySQL) ▪ 大数据平台 (Hadoop, Hive) ▪ 数据仓库 (Teradata, Snowflake) ▪ 文档存储系统 (SharePoint, Google Drive) ▪ API 和 Web 服务 大模型提取了以下信息: ▪ 表结构和字段定义 ▪ 存储位置和访问方法 ▪ 更新频率和最后修改日期 ▪ 数据所有者和维护者信息 (2)元数据增强 接下来,大模型分析现有的元数据,并进行以下增强: a) 智能描述生成 原始元数据: Table: CUSTOMER_TRX Columns: ▪ TRX_ID (NUMBER)
▪ CUSTOMER_ID (NUMBER) ▪ TRX_DATE (DATE) ▪ AMOUNT (NUMBER) ▪ STATUS (VARCHAR2)
大模型增强后: Table: CUSTOMER_TRX 描述:该表存储所有客户交易,包括已完成和待处理的交易。这是一个对财务报告和客户行为分析至关重要的表。 Columns: ▪ TRX_ID (NUMBER):每笔交易的唯一标识符。是该表的主键。
▪ CUSTOMER_ID (NUMBER):外键,引用CUSTOMERS表。用于识别进行交易的客户。 ▪ TRX_DATE (DATE):交易发生的日期。用于基于时间的分析和报告。 ▪ AMOUNT (NUMBER):交易金额,以公司的基础货币(美元)计。正值表示收入,负值表示退款或调整。 ▪ STATUS (VARCHAR2):交易的当前状态。可能的值包括'COMPLETED'(已完成)、'PENDING'(待处理)、'CANCELLED'(已取消)、'REFUNDED'(已退款)。对于对账流程至关重要。 更新频率:实时 数据敏感度:高(包含财务信息) 相关合规要求:PCI-DSS,GDPR(针对欧盟客户)
b) 数据质量评估 大模型分析数据样本,评估数据质量,并提供建议: 数据质量报告 - CUSTOMER_TRX: 1. 完整性:98.5% ▪ CUSTOMER_ID 有 1.5% 的空值。建议调查这些空值的来源。 2. 准确性:99.7% ▪ 0.3% 的 TRX_DATE 值是未来日期。可能由于时区问题或数据输入错误造成。 3. 一致性: ▪ 100% 的 STATUS 值与定义的枚举列表匹配。
▪ 99.9% 的 AMOUNT 值在预期范围内(-1,000,000 到 1,000,000)。 4. 时效性:数据实时更新,最新记录是 2 分钟前的。 建议: 1.在 TRX_DATE 字段实施约束,以防止出现未来日期。 2.调查 CUSTOMER_ID 空值的来源,并在数据录入点实施数据验证。 3.考虑为 AMOUNT 字段添加检查约束,以捕获潜在的数据输入错误。 c) 数据血缘关系映射 大模型分析数据流和依赖关系,生成数据血缘图:

(3)数据目录生成 基于增强后的元数据,大模型生成了一个全面的数据目录: ▪ 数据库: FINANCEDB 描述:金融交易和客户数据的主要数据库 表: ▶ PCI-DSS ▶ GDPR 字段: ▶ 名字: TRXID 描述:唯一交易标识符 类型:NUMBER 主键:是 ▶ 名字: CUSTOMERID 描述:客户引用 类型:NUMBER 外键:表: CUSTOMERS 字段: CUSTOMERID ... 其他字段 ... 相关报告: ▶ 每日交易汇总 ▶ 月度财务报表 ▶ 客户活动报告 访问控制: ▶ 角色:财务分析师 权限:SELECT ▶ 角色:财务经理 权限:SELECT, INSERT, UPDATE 数据质量:最后评估日期:2023-07-15 评分:98.5% 问题: ▶ 描述:1.5% 的 CUSTOMERID 值为空 严重程度:中等 行动计划:调查源系统 ▶ 表名: CUSTOMERTRX 描述:存储所有客户交易 所有者:财务部 管理员:John Doe (john.doe@globalfinance.com) 更新频率:实时 敏感度:高 合规要求: (4)智能搜索和推荐系统
大模型为数据目录提供了智能搜索和推荐功能: 用户查询: "我需要客户交易数据来分析客户行为" 大模型响应: 基于您的需求,我推荐以下数据资源: 1.主要数据集: CUSTOMER_TRX ▪ 包含所有客户交易信息
▪ 可用于分析交易模式、频率和金额 2. 补充数据集: a) CUSTOMERS: 提供客户背景信息,可用于分组分析 b) CUSTOMERACTIVITYLOG: 记录客户的非交易活动,有助于全面了解客户行为 3. 相关报告: ▪ "Customer Activity Report": 预制报告,提供客户行为摘要
▪ "Transaction Pattern Analysis Dashboard": 交互式仪表板,展示交易趋势 4. 注意事项: ▪ CUSTOMER_TRX 包含敏感财务信息,请确保遵守数据访问政策 ▪ 建议使用 CUSTOMER_ID 字段关联 CUSTOMERS 表以获取更多客户属性 5. 推荐的分析工具: ▪ Tableau: 已与 FINANCE_DB 集成,可直接连接分析 ▪ Python with Pandas: 用于更复杂的数据处理和机器学习模型构建如需进一步帮助,请联系数据管理员 Sarah Johnson (sarah.j@globalfinance.com) 成果和影响: 实施这个基于大模型的元数据管理和数据目录系统后,GlobalFinance 获得了以下收益: ▪ 数据发现时间减少了 70%,从平均 3 小时降至 54 分钟 ▪ 数据理解准确性提高了 40%,错误使用数据的情况大幅减少 ▪ 数据血缘关系清晰,使得影响分析和合规审计更加高效 ▪ 数据质量问题被及时发现和解决,整体数据质量提升了 15% ▪ 跨部门数据协作增加了 50%,促进了更多数据驱动的决策 ▪ 数据合规性得到加强,降低了数据泄露和违规使用的风险 通过利用大模型技术,GlobalFinance 成功地将其庞大而复杂的数据生态系统转变为一个组织有序、易于理解和高效利用的资源。这不仅提高了数据的价值,还为公司的数字化转型奠定了坚实的基础。
5、数据隐私和匿名化 理由:LLM可以理解数据的语义和上下文,帮助识别和保护敏感信息。当前政策驱动力强,性价比不错,在数据分级分类等安全领域具有广泛的应用场景,个人看好。 实用性:★★★★☆ (4星) 例子: MediCare Plus 是一家大型医疗保险公司,拥有数百万客户的敏感健康和财务数据。公司需要利用这些数据进行分析,以改进服务质量、预测健康趋势,并进行精算分析。然而,它们也必须保护客户隐私并遵守 HIPAA(健康保险携带和责任法案)等严格的法规。为解决这一挑战,MediCare Plus 开发了一个名为 HealthShield AI 的智能数据隐私和匿名化系统。 原始数据概览: MediCare Plus 的客户数据包含以下字段: ▪ 客户ID ▪ 姓名(名和姓) ▪ 出生日期 ▪ 社会安全号(SSN) ▪ 地址(街道、城市、州、邮编) ▪ 电话号码 ▪ 电子邮件地址 ▪ 性别 ▪ 种族/民族 ▪ 雇主信息 ▪ 收入水平 ▪ 保险计划类型 ▪ 保费金额 ▪ 索赔历史(日期、诊断代码、治疗代码、费用) ▪ 处方药物信息 ▪ 慢性病状况 ▪ 吸烟状态 ▪ 身高和体重(BMI) HealthShield AI 系统实施过程: (1)数据分类和风险评估 HealthShield AI 首先对数据进行分类和风险评估: ▪ 直接标识符:客户ID、姓名、SSN、电话号码、电子邮件地址 ▪ 准标识符:出生日期、地址、性别、种族/民族、雇主信息 ▪ 敏感属性:收入水平、保险计划类型、索赔历史、处方药物信息、慢性病状况、吸烟状态、BMI 系统评估每个字段的隐私风险级别: ▪ 高风险:SSN、完整地址、详细索赔历史 ▪ 中等风险:出生日期、雇主信息、收入水平 ▪ 低风险:性别、保险计划类型 (2)数据匿名化策略制定 基于风险评估,HealthShield AI 制定了以下匿名化策略: a) 删除直接标识符 b) 泛化准标识符 c) 部分抑制高风险数据 d) 添加统计噪音到敏感数值数据 e) 应用 k-匿名性 和 l-多样性 原则 (3)匿名化过程执行 HealthShield AI 执行以下匿名化步骤: a) 删除直接标识符: ▪ 删除客户ID、姓名、SSN、电话号码和电子邮件地址 b) 泛化准标识符: ▪ 出生日期:仅保留出生年份 ▪ 地址:仅保留州和邮编的前三位数字 ▪ 年龄:分组为 5 年间隔(如 25-30,31-35 等) ▪ 种族/民族:使用更广泛的类别(如将"古巴裔"泛化为"西班牙裔/拉丁裔") c) 部分抑制高风险数据: ▪ 索赔历史:保留诊断和治疗大类,删除具体代码 ▪ 处方药物:仅保留药物大类(如"降压药"而非具体药名) d) 添加统计噪音: ▪ 收入水平:在实际值的 ±5% 范围内添加随机噪音 ▪ 保费金额:在实际值的 ±3% 范围内添加随机噪音BMI:四舍五入到最接近的整数 e) 应用 k-匿名性 和 l-多样性: ▪ 确保每个准标识符组合至少有 k=5 个记录 ▪ 确保每个组内敏感属性至少有 l=3 个不同值 (4)数据转换示例 原始记录: 客户ID: 1234567 姓名: John Doe 出生日期: 1985-03-15 SSN: 123-45-6789 地址: 123 Main St, Springfield, IL 62701电话: (555) 123-4567 电子邮件: john.doe@email.com 性别: 男 雇主: ABC Corporation 收入: $75,000 保险计划: 白金计划 保费: $450/月 索赔: 2023-01-15, J45.901 (哮喘), 门诊就诊, $200 处方: Albuterol 吸入器 慢性病: 哮喘吸烟 状态: 从不身高/体重: 180cm / 80kg (BMI 24.7)
匿名化后的记录: 出生年份: 1985地址: IL 627** 性别: 男 雇主: 大型公司 收入: $73,500 - $76,500 保险计划: 高级计划 保费: $440 - $460/月 索赔: 2023, 呼吸系统疾病, 门诊就诊 处方: 支气管扩张剂 慢性病: 呼吸系统疾病吸烟 状态: 从不 BMI: 25
(5)数据质量和效用评估 HealthShield AI 评估匿名化后的数据质量和研究效用: ▪ 信息损失:计算原始数据和匿名化数据之间的信息熵差异 ▪ 统计特性保持:比较关键变量的均值、中位数、标准差等统计量 ▪ 机器学习模型性能:在原始数据和匿名化数据上训练预测模型,比较性能差异 例如,系统可能发现: ▪ 整体信息损失约为 15% ▪ 大多数统计特性的偏差在 3% 以内 ▪ 预测模型的准确率从 85% 下降到 82% (6)差分隐私实现 对于需要更高级别保护的聚合查询,HealthShield AI 实现了差分隐私机制: ▪ 设置隐私预算 ε = 1.0 ▪ 对敏感查询添加拉普拉斯噪音 ▪ 跟踪每次查询的隐私支出,确保总隐私支出不超过预算 例如,当查询"30-35岁年龄组的平均保费"时: 1.计算真实平均值:$500 2.确定敏感度:假设为 $100(单个记录可能对结果的最大影响) 3.生成拉普拉斯噪音:平均为 0,比例为 100/1.0 = 100 4.添加噪音到结果:$500 + 噪音(可能为 -$50) 5.返回结果:$450 (7)安全访问控制 HealthShield AI 还实施了严格的访问控制: ▪ 基于角色的访问控制(RBAC) ▪ 多因素身份认证 ▪ 详细的访问日志记录 ▪ 异常访问模式检测 例如,只有经过授权的研究人员可以访问匿名化数据,且每次访问都会记录详细的操作日志。 结果和影响: 通过实施 HealthShield AI 系统,MediCare Plus 实现了: ▪ 合规性:完全符合 HIPAA 和其他隐私法规要求 ▪ 数据效用:保持了 85% 的原始数据效用,足以支持大多数研究和分析需求 ▪ 风险降低:个人再识别风险从 5% 降低到 0.1% 以下 ▪ 研究促进:使得与学术机构的合作研究成为可能,而无需披露原始数据 ▪ 客户信任:提高了客户对公司数据处理实践的信心 ▪ 创新支持:能够安全地利用大数据分析来改进产品和服务 例如,使用匿名化数据,MediCare Plus 成功地: ▪ 识别了某些慢性病的早期预警指标 ▪ 优化了保险产品定价策略 ▪ 开发了个性化的健康管理建议系统 通过 HealthShield AI,MediCare Plus 不仅保护了客户隐私,还释放了数据的巨大价值,推动了业务创新和改进。
6、智能数据集成 理由:LLM可以理解不同数据源的结构和语义,帮助自动映射和集成数据。但数据集成涉及复杂的系统间交互和业务规则理解,全面自动化仍然面临挑战。业界很早提出的数据编织概念与其类似,但数据编制现在投入实用化的很少,因为很多企业没有那么多的数据源需要智能集成。 实用性:★★☆☆☆ (2星) 例子: GlobalRetail 是一家跨国零售企业,在全球拥有数百家实体店和电子商务平台。公司决定构建一个统一的客户数据平台(CDP),以提供360度客户视图。这需要整合来自多个不同系统的客户数据。 数据源概览: ▪ 实体店销售系统(自研):存储在 Oracle 数据库中 ▪ 电子商务平台(Shopify):使用 API 访问 ▪ 客户服务系统(Zendesk):提供 CSV 文件导出 ▪ 会员管理系统(自研):存储在 SQL Server 中 ▪ 营销自动化平台(Marketo):使用 API 访问 智能数据源分析过程: 智能集成平台使用大模型技术对每个数据源进行深入分析: (1)实体店销售系统分析 平台连接到 Oracle 数据库,分析表结构、字段类型和样本数据。 发现: ▪ 客户相关表: CUSTOMERS, TRANSACTIONS, STORE_VISITS ▪ 关键字段: ▪ CUSTOMERS: CUSTOMER_ID (主键), NAME, EMAIL, PHONE, ADDRESS ▪ TRANSACTIONS: TRANSACTIONID, CUSTOMERID (外键), DATE, TOTAL_AMOUNT ▪ STORE_VISITS: VISITID, CUSTOMERID (外键), STOREID, VISITDATE 平台识别出 CUSTOMER_ID 是连接这些表的关键字段,并推断出客户购买历史可以通过 TRANSACTIONS 表获取。 (2)电子商务平台分析 平台通过 Shopify API 获取数据结构和样本数据。 发现: ▪ 相关端点: /customers, /orders ▪ 关键字段: ▪ /customers: id, email, firstname, lastname, total_spent ▪ /orders: id, customerid, createdat, totalprice, lineitems 平台注意到客户名字在这里被分为 first_name 和 last_name,而在实体店系统中是单个 NAME 字段。 (3)客户服务系统分析 平台分析从 Zendesk 导出的 CSV 文件。 发现: ▪ 文件包含:tickets.csv, users.csv ▪ 关键字段: ▪ users.csv: id, name, email, phone ▪ tickets.csv: id, requesterid, subject, createdat, status 平台识别出 users.csv 中的 id 对应 tickets.csv 中的 requester_id,建立了客户和服务请求之间的关联。 (4)会员管理系统分析 平台连接到 SQL Server 数据库,分析表结构和数据。 发现: ▪ 主要表: Members, MembershipLevels, Points ▪ 关键字段: ▪ Members: MemberID, FullName, Email, JoinDate, MembershipLevelID ▪ MembershipLevels: LevelID, LevelName, PointsRequired ▪ Points: PointID, MemberID, PointsEarned, TransactionDate 平台推断出会员等级是基于积分系统,这是其他数据源中没有的信息。 (5)营销自动化平台分析 平台通过 Marketo API 获取数据结构。 发现: ▪ 主要对象: Lead, Campaign, CampaignMembership ▪ 关键字段: ▪ Lead: id, email, firstName, lastName, company ▪ Campaign: id, name, description, type ▪ CampaignMembership: leadId, campaignId, status 平台注意到这里的 Lead 概念大致对应于其他系统中的 "客户" 或 "会员"。 智能模式映射: 基于对所有数据源的分析,智能集成平台进行以下模式映射: (1)客户标识映射: ▪ 创建统一的 GLOBAL_CUSTOMER_ID ▪ 映射关系: ▶ 实体店系统 CUSTOMERS.CUSTOMER_ID ▶ Shopify customers.id ▶ Zendesk users.id ▶ 会员系统 Members.MemberID ▶ Marketo Lead.id (2)客户基本信息映射: ▪ 创建统一的客户信息结构: ▶ FULL_NAME: 合并 Shopify 的 first_name 和 last_name;拆分其他系统的单一名字字段 ▶ EMAIL: 所有系统都有这个字段,直接映射 ▶ PHONE: 不是所有系统都有,需要进行数据补全 ▶ ADDRESS: 主要从实体店系统和电子商务平台获取,可能需要标准化处理 (3)购买历史映射: ▪ 合并实体店 TRANSACTIONS 和 Shopify orders 数据 ▪ 统一字段: ▶ TRANSACTION_ID: 包含来源标识(如 "STORE" 或 "ONLINE" 前缀) ▶ DATE: 标准化所有日期格式 ▶ AMOUNT: 统一货币单位和精度 (4)客户服务历史映射: ▪ 主要来源于 Zendesk tickets.csv ▪ 创建 SERVICE_INTERACTIONS 结构,包含: ▶ INTERACTION_ID ▶ GLOBAL_CUSTOMER_ID ▶ DATE ▶ TYPE (例如:"complaint", "inquiry", "feedback") ▶ STATUS ▶ RESOLUTION_TIME (5)会员信息映射: ▪ 创建 MEMBERSHIP 结构,包含: ▶ GLOBAL_CUSTOMER_ID ▶ LEVEL: 从 MembershipLevels 表获取 ▶ POINTS: 从 Points 表汇总 ▶ JOIN_DATE: 来自 Members.JoinDate (6)营销互动映射: ▪ 创建 MARKETING_INTERACTIONS 结构,包含: ▶ GLOBAL_CUSTOMER_ID ▶ CAMPAIGN_ID ▶ CAMPAIGN_NAME ▶ INTERACTION_TYPE (如 "emailopen", "click", "formsubmission") ▶ DATE 智能处理示例: ▪ 名称处理:对于 "John Doe" 这样的全名,平台能够智能拆分为 "John" 和 "Doe";反之,也能将分开的名字正确组合。 ▪ 地址标准化:识别并标准化不同格式的地址,如将 "Apt. 4, 123 Main St., New York, NY 10001" 和 "123 Main Street, Apartment 4, New York, New York, 10001" 标准化为统一格式。 ▪ 重复客户识别:使用模糊匹配算法,识别可能的重复客户记录。例如,"John Doe" 和 "Jon Doe" 可能是同一个人,系统会标记这种情况以供人工审核。 ▪ 数据补全:如果在 Shopify 系统中发现了一个新客户,但在会员系统中没有对应记录,平台会自动创建一个会员记录,并标记为 "待确认" 状态。 ▪ 跨系统购买行为分析:平台能够识别一个客户在实体店和在线商店的购买模式,创建统一的购买历史视图。 通过这种智能的数据源分析和模式映射,GlobalRetail 能够创建一个全面、准确的客户数据平台,为精准营销、个性化服务和业务决策提供强大支持。
7、自动化数据文档生成 理由:这是LLM的强项,能够基于数据结构和内容生成易懂的文档,应用场景广泛,但考虑到实际IT的现状,我觉得最大的应用场景大概是为了满足某种合规性。 实用性:★★★☆☆ (3星)
例子: GlobalRetail 是一家跨国零售巨头,拥有复杂的数据生态系统,包括销售、库存、客户、供应链等多个领域的数据。随着数据量的迅速增长和系统的不断演变,维护最新、准确的数据文档变得越来越具有挑战性。传统的手动文档编写方法不仅耗时耗力,而且经常导致文档过时或不完整。 为解决这一问题,GlobalRetail 开发了一个名为 DocuMind AI 的智能数据文档生成系统。这个系统能够自动分析公司的各种数据源,生成全面、准确、易懂的数据文档。
DocuMind AI 系统实施过程: (1)数据源连接和扫描 DocuMind AI 首先连接并扫描 GlobalRetail 的各种数据源: ▪ 企业资源规划(ERP)系统 ▪ 客户关系管理(CRM)系统 ▪ 仓库管理系统(WMS) ▪ 电子商务平台 ▪ 财务系统 ▪ 人力资源管理系统 系统自动识别表结构、字段类型、关系、约束等元数据信息。 (2)智能数据分析 DocuMind AI 对收集到的元数据进行深入分析: ▪ 数据分布分析:了解每个字段的值分布、常见值、异常值等 ▪ 数据质量评估:检查数据完整性、准确性、一致性 ▪ 数据关系推断:识别表间关系,如主键-外键关系 ▪ 数据使用模式分析:跟踪数据访问日志,了解数据的使用频率和方式 (3)上下文信息收集 系统通过多种方式收集数据的上下文信息: ▪ 分析现有文档和注释 ▪ 检查相关的代码仓库和数据处理脚本 ▪ 审查数据相关的业务流程文档 ▪ 与数据管理员和业务用户进行自动化问答交互 (4)文档生成 基于收集和分析的信息,DocuMind AI 自动生成多种类型的数据文档: a) 数据字典 b) 数据流图 c) 实体关系图 d) 数据血缘图 e) 数据质量报告 f) 使用指南 让我们详细看看其中几种文档的生成过程和内容: a) 数据字典生成 以销售数据为例,DocuMind AI 生成的数据字典包含: 表名:SALES_TRANSACTIONS

字段说明: ▪ TRANSACTION_ID: 每笔交易的唯一标识符。格式为 'TR' 后跟 9 位数字。 ▪ STORE_ID: 进行销售的实体店铺ID。与 STORES 表关联以获取店铺详细信息。 ▪ PRODUCT_ID: 销售产品的唯一标识符。与 PRODUCTS 表关联以获取产品详细信息。 ▪ SALE_DATE: 交易发生的日期。用于时间序列分析和报告。 ▪ QUANTITY: 销售的产品数量。必须为正整数。 ▪ UNIT_PRICE: 产品的单价,精确到分。 ▪ TOTALAMOUNT: 交易的总金额,应等于 QUANTITY * UNITPRICE。 ▪ PAYMENT_METHOD: 客户使用的支付方式。限于预定义的几种类型。 ▪ CUSTOMER_ID: 如果是会员购买,则记录客户ID。非会员购买时为空。 使用注意: ▪ 该表每天接收约 500 万条新记录。 ▪ TOTAL_AMOUNT 字段用于财务报告和销售分析,确保其准确性至关重要 ▪ CUSTOMER_ID 的完整性较低是因为许多交易来自非会员顾客,这是正常现象。 b) 数据流图生成 DocuMind AI 生成的数据流图展示了销售数据从产生到最终使用的整个流程: [销售终端] --> (实时数据流) --> [交易处理系统]
[交易处理系统] --> (批量传输, 每小时) --> [数据仓库] [数据仓库] --> (数据转换) --> [销售报表系统] [数据仓库] --> (数据聚合) --> [预测分析系统] [销售报表系统] --> (数据可视化) --> [管理仪表板] [预测分析系统] --> (预测结果) --> [库存管理系统] [预测分析系统] --> (客户洞察) --> [CRM系统]
流程说明: ▪ 销售数据首先在销售终端(如收银机、网站)产生。 ▪ 数据实时传输到交易处理系统进行初步处理和验证。 ▪ 每小时,交易数据被批量传输到中央数据仓库。 ▪ 在数据仓库中,原始数据经过清洗和转换,准备用于报告和分析。 ▪ 转换后的数据传输到销售报表系统,生成各类标准报告。 ▪ 同时,数据被用于预测分析,生成销售预测和客户洞察。 ▪ 预测结果用于优化库存管理和个性化营销。 c) 使用指南生成 DocuMind AI 生成的使用指南包括: 1. 数据访问方法 ▪ 直接数据库访问:提供了连接字符串模板和访问凭证申请流程。
▪ API 访问:详细说明了 REST API 端点、认证方法和使用示例。 ▪ 报表工具访问:列出了已配置的 Tableau 和 Power BI 报表,以及如何请求新报表。 2. 常见查询场景 ▪ 日销售额统计:提供了 SQL 查询模板和注意事项。 ▪ 畅销产品分析:包括查询逻辑和性能优化建议。 ▪ 客户购买行为分析:说明了如何结合 SALES_TRANSACTIONS 和 CUSTOMERS 表进行分析。 3. 数据更新周期 ▪ 实时数据:说明了哪些字段实时更新,以及实时数据的延迟范围。 ▪ 批量更新数据:列出了每日、每周、每月更新的数据项及其具体更新时间。 4. 数据质量监控 ▪ 介绍了自动化数据质量检查的方法和工具。 ▪ 提供了数据质量问题报告的流程和联系人。 5. 安全和合规 ▪ 详细说明了数据的敏感级别和相应的处理要求。 ▪ 提供了数据脱敏和匿名化的指导。 6.支持和帮助 ▪ 列出了数据相关问题的联系人和支持渠道。 ▪ 提供了常见问题解答(FAQ)部分。 结果和影响: 通过实施 DocuMind AI 系统,GlobalRetail 实现了以下成果: ▪ 文档生成效率:将文档生成时间从平均 2 周缩短到 2 小时。 ▪ 文档准确性:文档的错误率从 15% 降低到不到 1%。 ▪ 文档完整性:数据字段的文档覆盖率从 60% 提高到 99%。 ▪ 用户满意度:数据使用者对文档的满意度从 65% 提升到 95%。 ▪ 数据使用效率:新分析项目的启动时间平均缩短了 40%。 ▪ 合规性:显著降低了由于误解数据而导致的合规风险。 具体例子: ▪ 市场分析团队利用详细的数据字典,快速识别了客户忠诚度相关的关键字段,开发出新的客户细分模型,提高了营销效率。 ▪ IT 团队使用自动生成的数据流图,迅速定位并解决了一个长期存在的数据同步问题,提高了整体系统性能。 ▪ 新入职的数据科学家通过使用指南,在入职后的一周内就能独立进行复杂的销售预测分析,大大缩短了入职培训时间。 通过 DocuMind AI,GlobalRetail 不仅提高了数据管理的效率,还显著增强了整个组织的数据素养和数据驱动决策能力。
8、智能数据建模 理由:数据建模需要深入理解业务逻辑和系统架构,LLM可以提供辅助,但难以完全自动化这个过程。逻辑简单的清单级建模场景可以考虑尝试。 实用性:★★☆☆☆ (2星) 例子: ElectroMart 是一家快速成长的在线电子产品零售商。公司决定构建一个数据仓库,以支持销售分析、库存管理和客户行为洞察。ElectroMart 的 IT 团队向大模型提供了业务需求和现有数据结构,请求协助设计数据仓库模型。 输入信息: (1)业务需求描述:"我们需要分析产品销售趋势、评估营销活动效果、优化库存水平,并了解客户购买行为。我们想追踪不同类别产品在各时间段的销售情况,分析客户的购买历史和偏好,以及评估各种促销活动的影响。同时,我们需要监控库存水平,避免缺货或积压。" (2)现有主要数据表结构: ▪ 订单表 (Orders): - OrderID, CustomerID, OrderDate, TotalAmount, ShippingAddress ▪ 订单详情表 (OrderDetails):- OrderDetailID, OrderID, ProductID, Quantity, UnitPrice ▪ 产品表 (Products): - ProductID, ProductName, CategoryID, SupplierID, UnitPrice, StockQuantity ▪ 客户表 (Customers): - CustomerID, FirstName, LastName, Email, RegistrationDate ▪ 类别表 (Categories): - CategoryID, CategoryName, Description ▪ 库存日志表 (InventoryLog): - LogID, ProductID, ChangeDate, QuantityChange, Reason ▪ 营销活动表 (MarketingCampaigns): - CampaignID, CampaignName, StartDate, EndDate, DiscountRate 大模型分析和建模过程: (1)需求分析大模型分析业务需求,识别关键分析维度和指标: 输出: 关键分析维度: ▪ 时间(日期、月份、季度、年份)
▪ 产品 ▪ 客户 ▪ 地理位置(基于送货地址) ▪ 营销活动
主要分析指标: ▪ 销售额
▪ 销售数量 ▪ 平均订单价值 ▪ 库存水平 ▪ 客户购买频率 ▪ 营销活动转化率 (2)模型类型推荐基于需求和现有数据结构,大模型推荐数据仓库模型: 输出: 推荐模型:星型模式(Star Schema) 理由: 1.分析需求主要围绕销售、库存和客户行为,这些可以作为核心事实表。 2.有明确的分析维度(时间、产品、客户等),适合构建维度表。 3.星型模式查询性能好,适合复杂的分析查询。 4.相较于雪花模式,星型模式更易于理解和维护,适合ElectroMart当前的需求复杂度。 5.可以方便地扩展以包含新的分析维度或指标。
(3)具体模型设计大模型设计详细的星型模式,包括维度表和事实表: 输出: 维度表设计: 1.日期维度表 (DimDate) ▪ DateKey (PK)
▪ FullDate ▪ DayOfWeek ▪ DayName ▪ DayOfMonth ▪ DayOfYear ▪ WeekOfYear ▪ MonthName ▪ MonthOfYear ▪ Quarter ▪ Year ▪ IsWeekend ▪ IsHoliday 1.产品维度表 (DimProduct) ▪ ProductKey (PK) ▪ ProductID (Natural Key) ▪ ProductName ▪ CategoryID ▪ CategoryName ▪ SupplierID ▪ SupplierName ▪ UnitPrice ▪ ProductAddedDate ▪ IsDiscontinued 1.客户维度表 (DimCustomer) ▪ CustomerKey (PK) ▪ CustomerID (Natural Key) ▪ FirstName ▪ LastName ▪ Email ▪ RegistrationDate ▪ CustomerSegment 1.地理维度表 (DimGeography) ▪ GeographyKey (PK) ▪ City ▪ State ▪ Country ▪ PostalCode 1.营销活动维度表 (DimCampaign) ▪ CampaignKey (PK) ▪ CampaignID (Natural Key) ▪ CampaignName ▪ StartDateEndDate ▪ DiscountRate ▪ CampaignType 事实表设计: 1.销售事实表 (FactSales) ▪ SalesKey (PK)
▪ DateKey (FK to DimDate) ▪ ProductKey (FK to DimProduct) ▪ CustomerKey (FK to DimCustomer) ▪ GeographyKey (FK to DimGeography) ▪ CampaignKey (FK to DimCampaign) ▪ OrderID ▪ Quantity ▪ UnitPrice ▪ DiscountAmount ▪ SalesAmount ▪ Cost ▪ Profit 1.库存事实表 (FactInventory) ▪ InventoryKey (PK) ▪ DateKey (FK to DimDate) ▪ ProductKey (FK to DimProduct) ▪ StockQuantity ▪ ReceiptQuantity ▪ ShippedQuantity ▪ OnOrderQuantity ▪ StockValue 1.客户行为事实表 (FactCustomerBehavior) ▪ BehaviorKey (PK) ▪ DateKey (FK to DimDate) ▪ CustomerKey (FK to DimCustomer) ▪ ProductKey (FK to DimProduct) ▪ PageViews ▪ TimeSpentOnProduct ▪ AddToCartCount ▪ PurchaseCount (4)设计决策说明大模型解释主要设计决策: 输出: 设计决策说明: 1.星型模式选择: ▪ 原因:提供良好的查询性能和足够的灵活性
▪ 优势:简化ETL过程,便于业务用户理解 2.日期维度的详细设计: ▪ 包含多种时间属性,支持各种时间尺度的分析 ▪ 添加IsWeekend和IsHoliday字段,便于分析这些特殊日期的销售情况 3. 产品维度表中加入类别和供应商信息: ▪ 避免了雪花模式,简化了查询 ▪ 权衡:可能导致一些数据冗余,但考虑到查询性能和简化性,这是可接受的 4. 地理维度表的引入: ▪ 基于送货地址信息,支持地理位置相关的销售分析 ▪ 允许进行多层次的地理分析(国家、州/省、城市级别) 5. 销售事实表的设计: ▪ 包含了数量、单价、折扣等详细信息,支持灵活的销售分析 ▪ 加入了成本和利润字段,直接支持盈利能力分析 6. 库存事实表的单独设计: ▪ 分离自销售事实表,因为库存变动不仅由销售引起 ▪ 包含了收货和在途订单数量,支持全面的库存分析 7. 客户行为事实表的引入: ▪ 捕捉客户在购买前的行为,支持转化漏斗分析 ▪ 有助于理解产品受欢迎程度和客户兴趣 8. 使用代理键: ▪ 在所有维度表中使用代理键(如CustomerKey而不是CustomerID) ▪ 提高了查询性能,并支持缓慢变化维度的实现 (5)未来扩展建议大模型提供前瞻性建议: 输出: 未来扩展建议: 1.考虑添加供应商维度表,以支持更详细的供应链分析 2.可以开发一个退货事实表,以分析退货原因和模式 3.如果引入会员制度,可以扩展客户维度表以包含会员等级信息 4.考虑实现缓慢变化维度(SCD)类型2,特别是对于产品和客户维度,以跟踪历史变化 5.如果业务扩展到实体店,考虑添加店铺维度 6.可以考虑引入产品评论事实表,捕捉客户反馈数据
通过这个详细的过程,大模型展示了如何从业务需求和现有数据结构出发,设计出一个全面的星型模式数据仓库。它不仅提供了具体的表结构设计,还解释了每个关键决策的理由,并给出了前瞻性的建议,体现了其在数据建模方面的强大能力。
9、数据合规性检查 理由:LLM可以理解复杂的法规要求,但合规性检查通常需要高度准确性和可解释性,可以作为当前数据安全评估的一种辅助手段,特别适合在审核流程中嵌入,但可能需要更多的人工参与和验证。 实用性:★★★☆☆ (3星) 例子: GlobalBank 是一家运营在欧盟、美国和亚洲的大型跨国金融机构。随着数据保护法规的不断演变和各地区法规的差异,GlobalBank 面临着复杂的数据合规挑战。公司决定使用基于大模型的系统来进行全面的数据合规性检查。 数据概览: GlobalBank 的数据包括: ▪ 客户个人信息 ▪ 交易记录 ▪ 信用评分数据 ▪ 投资组合信息 ▪ 员工数据 ▪ 风险评估报告 这些数据分布在不同地区的多个数据中心,并受到不同的本地和国际法规约束。 大模型合规性检查过程: (1)法规理解和映射 大模型首先分析并理解适用的各种数据保护和金融法规: 欧盟:GDPR (通用数据保护条例) ▪ 美国:CCPA (加州消费者隐私法案), GLBA (金融服务现代化法案) ▪ 中国:个人信息保护法 ▪ 国际:BCBS 239 (巴塞尔银行监管委员会) 大模型创建了一个详细的合规要求映射: GDPR 要求: ▪ 数据最小化
▪ 存储限制 ▪ 数据主体权利(访问、删除、更正) ▪ 数据处理的法律基础 ▪ 数据泄露通知CCPA 要求: ▪ 消费者知情权 ▪ 选择退出数据销售的权利 ▪ 数据访问和删除权中国个人信息保护法要求: ▪ 数据本地化 ▪ 跨境数据传输限制 ▪ 个人同意要求 BCBS 239 要求: ▪ 风险数据聚合能力
▪ 风险报告实践 (2)数据分类和映射 大模型分析 GlobalBank 的数据结构,并将其映射到相关法规: 示例映射: 1. 客户个人信息: ▪ 适用: GDPR, CCPA, 中国个人信息保护法
▪ 关键要求: 数据最小化, 存储限制, 数据主体权利 2. 交易记录: ▪ 适用: GDPR, GLBA, BCBS 239 ▪ 关键要求: 数据安全, 存储限制, 风险数据聚合 3. 信用评分数据: ▪ 适用: GDPR, FCRA (美国公平信用报告法) ▪ 关键要求: 数据准确性, 数据主体权利, 使用限制 4.员工数据: ▪ 适用: GDPR, 各地劳动法 ▪ 关键要求: 数据保护, 存储限制, 跨境传输限制 (3)深度合规性分析 大模型对每类数据进行深入分析,识别潜在的合规问题: 分析示例 - 客户个人信息: 1.数据最小化审查: 发现: 存储了客户的宗教信仰信息 分析: 除非有特定的合法业务需求,否则这属于过度收集 建议: 审查此数据的必要性,如无必要则删除 2.存储限制检查: 发现: 部分已关闭账户的客户数据保留超过7年 分析: 可能违反GDPR的存储限制原则 建议: 实施数据留存政策,定期清理过期数据 3.跨境数据传输分析: 发现: 欧洲客户数据被传输到美国数据中心 分析: 需要确保符合GDPR的跨境数据传输要求 建议: 审查数据传输机制,考虑实施标准合同条款或获得明确同意 4.数据主体权利支持: 发现: 系统缺乏自动化机制来响应数据访问和删除请求 分析: 可能难以及时满足GDPR和CCPA的要求 建议: 开发自动化工具以处理数据主体请求 5.同意管理: 发现: 营销同意记录不完整 分析: 可能违反GDPR的明确同意要求 建议: 更新同意管理系统,确保记录完整的同意历史
(4)风险评估和优先级排序 大模型评估每个发现的合规问题,并根据严重性和潜在影响进行优先级排序: 高优先级问题: 1.跨境数据传输合规性 风险: 高 潜在影响: GDPR违规罚款可达全球年收入的4% 紧迫性: 立即行动 2.过度数据收集(宗教信仰信息) 风险: 高 潜在影响: 监管处罚、声誉损害 紧迫性: 1个月内解决 中优先级问题: 1.数据留存政策实施 风险: 中 潜在影响: 合规风险,存储成本增加 时间框架: 3个月内实施 2.数据主体权利响应机制 风险: 中 潜在影响: 客户不满,轻微合规风险 时间框架: 6个月内开发和部署 低优先级问题: 1.营销同意记录完善 风险: 低 潜在影响: 小规模合规风险 时间框架: 长期持续改进
(5)合规性改进建议 基于分析结果,大模型提供了详细的改进建议: 1. 跨境数据传输: ▪ 实施加密机制确保数据传输安全
▪ 与美国数据中心签署标准合同条款 ▪ 考虑在欧盟建立本地数据中心以minimise数据传输 2. 数据最小化: ▪ 审查所有数据字段的必要性 ▪ 制定明确的数据收集政策,限制敏感信息的收集 ▪ 实施技术措施,自动过滤和删除非必要数据 3. 数据留存: ▪ 制定全面的数据留存政策 ▪ 实施自动化数据归档和删除系统 ▪ 定期审查和更新留存政策以适应新的法规要求 4. 数据主体权利: ▪ 开发中央化的数据主体请求处理平台 ▪ 实施身份验证机制以确保安全访问 ▪ 建立跨部门工作流以高效处理复杂请求 5. 同意管理: ▪ 升级CRM系统以捕获详细的同意记录 ▪ 实施定期同意刷新机制 ▪ 提供客户友好的同意管理界面 结果和影响: 通过使用大模型进行全面的数据合规性检查,GlobalBank 实现了以下成果: ▪ 全面的合规性评估:深入了解了全球业务的合规状况。 ▪ 风险缓解:识别并解决了几个高风险的合规问题,降低了潜在的法律和金融风险。 ▪ 效率提升:自动化的合规性检查显著减少了人工审查时间。 ▪ 前瞻性规划:制定了长期的合规性战略,为未来的监管变化做好准备。 ▪ 声誉保护:通过主动的合规管理,增强了客户和监管机构的信任。
10、异常检测和数据质量监控 理由:LLM可以学习正常的数据模式,快速识别异常或不一致的数据点,但传统的统计方法和专门的机器学习模型在这个领域可能更加有效和可靠。智能体出现后,LLM可能会有一些用武之地,但定制化要求很高,实现复杂。 实用性:★☆☆☆☆ (1星) 例子: 某大型石化厂拥有6台乙烯裂解炉,每台年产能约60万吨乙烯。2号裂解炉在过去一年中出现了3次非计划停机,造成了巨大的经济损失。工厂决定在2号裂解炉上试点部署基于LLM的智能预测性维护系统。 实施过程: (1)数据收集与预处理 a) 结构化数据样本: ▪ 温度传感器T-2103读数:时间戳: 2023-06-15 10:30:15, 值: 842.5°C 时间戳: 2023-06-15 10:31:15, 值: 843.1°C 时间戳: 2023-06-15 10:32:15, 值: 844.2°C ▪ 压力传感器P-2103读数:时间戳: 2023-06-15 10:30:15, 值: 2.15 MPa 时间戳: 2023-06-15 10:31:15, 值: 2.16 MPa 时间戳: 2023-06-15 10:32:15, 值: 2.17 MPa b) 非结构化数据样本: ▪ 操作员日志摘录:"2023年6月15日上午班:2号炉北区管束温度波动较大,疑似焦炭堆积。已调整蒸汽比+2%,继续观察。" ▪ 维修记录摘录:"2023年5月20日检修:2号炉更换3根破损盘管,发现北区管束内壁结焦严重,建议缩短清洗周期。" (2)LLM训练与微调 a) 领域词汇示例: ▪ 专业术语:裂解炉、焦炭堆积、盘管、结焦、蒸汽比 ▪ 设备代号:T-2103(温度传感器)、P-2103(压力传感器) b) 故障案例训练数据: 案例1:输入:"2号炉北区管束温度在6小时内上升8°C,压力增加0.1MPa,上次清洗是45天前。 "标签:"管束结焦预警,建议增加蒸汽比并安排清洗。" 案例2:...(更多类似案例)
(3)系统部署与集成 硬件配置: ▪ 2台NVIDIA A100 GPU服务器用于LLM推理 ▪ 1台数据预处理服务器 ▪ 10台边缘计算设备用于实时数据采集 软件架构: ▪ 数据采集层:使用OSIsoft PI系统收集实时数据 ▪ 数据处理层:Apache Kafka用于数据流处理 ▪ AI推理层:使用NVIDIA Triton推理服务器部署LLM ▪ 应用层:基于React的Web界面,用于展示分析结果和接收操作员输入 (4)实际运行案例 日期:2023年6月15日 a) 系统检测到的异常: 10:45 AM - LLM分析了最近4小时的数据,发现以下异常: ▪ T-2103温度持续上升,从830°C升至844°C
▪ P-2103压力缓慢增加,从2.10 MPa升至2.17 MPa ▪ 北区管束的四个温度传感器读数差异增大 b) LLM生成的分析报告: 警报等级:黄色(需要关注)
问题描述:2号裂解炉北区管束可能存在局部结焦情况 证据: 1.温度传感器T-2103显示4小时内温度上升14°C,超过正常波动范围 2.压力传感器P-2103显示压力缓慢上升,符合结焦导致的流阻增加特征 3.北区管束温度分布不均,最高点与最低点温差达到28°C,超过正常15°C的阈值 4.查阅历史记录,距离上次清洗已有43天,接近建议的45天清洗周期 可能原因: 5.原料质量波动导致结焦加剧(可能性:75%) 6.蒸汽比例不足,未能有效抑制结焦(可能性:60%) 7.局部流体分布不均,导致热点形成(可能性:40%) 建议措施: 8.立即增加蒸汽比例2%,监测30分钟后的效果 9.检查原料组分,特别是重质原料的含量 10.准备在24小时内进行在线除焦操作 11.如情况未得到改善,考虑在72小时内安排停车清洗 需要进一步信息: 1.最近一周的原料组分分析报告 2.上游脱硫装置的运行状况
c) 操作员反馈与系统响应:操作员输入: "蒸汽比已调整。最近原料中重质组分确实有所增加,脱硫装置两天前更换了催化剂。"
LLM响应: 感谢提供额外信息。基于您的反馈,我更新了分析: 1.原料组分变化很可能是导致结焦加剧的主要原因。重质组分增加会提高结焦倾向。 2.脱硫装置催化剂更换可能暂时影响了脱硫效果,间接增加了结焦风险。更新建议: 3.继续观察蒸汽比调整的效果,如30分钟内温度开始下降,可维持当前参数 4.建议在12小时内对原料进行详细分析,特别关注硫含量和重质芳烃含量 5.与脱硫装置团队沟通,确认新催化剂的活性是否达到预期 6.考虑临时降低原料处理量5%,直到情况稳定或完成下一次清洗 请在2小时后提供温度和压力的最新数据,我们将重新评估情况。 (5)结果追踪 ▪ 12小时后:温度稳定在835°C左右,压力略有下降 ▪ 48小时后:完成在线除焦,设备参数恢复正常 ▪ 1周后:原料质量问题得到解决,脱硫装置性能恢复 ▪ 1个月后:2号裂解炉运行稳定,未出现异常波动 (6)系统迭代优化 ▪ 收集此次事件的完整数据和处理过程,加入训练集 ▪ 更新知识库,加入"脱硫装置催化剂更换"对裂解炉的潜在影响 ▪ 优化报警阈值,将原料组分变化纳入预警因素 实际效果: ▪ 及时发现并处理了潜在的结焦问题,避免了可能的非计划停机 ▪ 相比传统方法,提前3-5天发现问题,为管理层决策赢得了宝贵时间 ▪ 系统的建议帮助操作员快速定位根本原因,减少了诊断时间 ▪ 通过持续学习,系统对类似情况的预测准确率从初始的75%提升到90%
这个真实案例展示了LLM如何在复杂的工业环境中处理多源数据,进行智能分析和决策支持。它不仅能处理结构化的传感器数据,还能理解和利用非结构化的文本信息,如操作员日志和维修记录。通过持续学习和优化,系统能够不断提高其预测和诊断能力,为化工厂的安全生产和效率提升提供了强有力的支持。 总体来讲,大模型在数据自身领域的应用场景还是有限的,从这个角度来讲,数据专业人士更应该向外看,用大数据+大模型的能力去赋能别人。
(以上内容摘录自互联网,如有侵权请联系删除) |