登录EABOK更精彩
快捷登录
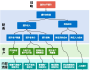
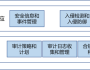
解决一物多码,多品牌食品集团主数据管理实践
只看大图 / 倒序浏览 © 文章版权由 admin 解释,禁止匿名转载
回答数
0
浏览数
712
收藏数
成为第一个回答人
2025-03-08
2025-02-11
2025-02-07
2025-01-25
2025-01-13
管理员
99
2025-3-8
2025-2-11
2025-2-7
2025-1-25
2025-1-13