在DAMA中,讲数据本身管理的一共有四种数据,参考数据、主数据、元数据及文件和内容管理,以前我们讲前三者的居多,而文件和内容管理,即非结构化数据谈的很少。因为我们以前搞数据,基本还是以关系型数据库的结构化数据为主的。
但随着大模型时代的到来,对非结构化数据的管理将成为下一个时代数据管理的核心,今天就来谈一谈,希望让大家对非结构化数据有个基本全面的理解。
一、引言
1、非结构化数据的定义 非结构化数据是指那些不遵循固定模式或不具有预定义数据模型的数据。与结构化数据(如数据库中的表格数据)不同,非结构化数据没有固定的格式,其内容和结构通常由数据的自然形式决定。 以下是非结构化数据的八大关键特征:


2、非结构化数据的重要性 非结构化数据提供了丰富的信息来源和商业洞察,帮助企业改善客户体验、提高运营效率、促进创新、增强竞争优势,并确保法律合规。 下图列出了非结构化数据的八大价值:

详细描述见下表:

案例一:零售行业的客户反馈分析通过分析客户在社交媒体和电商平台上的评论,零售企业可以了解产品的优缺点,及时调整产品策略和市场营销策略,提升客户满意度。 案例二:医疗行业的影像分析利用人工智能技术分析医学影像数据,可以辅助医生诊断疾病,提高诊断的准确性和效率。例如,早期的癌症筛查可以通过图像分析技术发现微小的病变,提高患者的治愈率。 案例三:金融行业的欺诈检测通过分析非结构化数据如电话录音和电子邮件内容,结合结构化的交易数据,金融机构可以更早地发现和预防欺诈行为,保护客户资产安全。
二、非结构化数据的类型与特点
非结构化数据类型多种多样,以下是一些主要类型及其详细说明:

1. 文本数据 ▪ 电子邮件:包含正文、附件、元数据(如时间戳、发件人和收件人信息)等。企业通过分析电子邮件内容可以挖掘客户需求、监控员工沟通等。 ▪ 文档:如Word、PDF、TXT等格式的文档。这些文档中包含大量业务信息、报告、合同等重要内容。 ▪ 社交媒体内容:包括微博、微信、Facebook、Twitter等社交平台上的帖子、评论和私信。这些数据能够反映公众情绪和市场趋势。 ▪ 网络内容:如博客文章、论坛帖子、新闻报道和在线评论等。企业可以通过这些内容了解行业动态和竞争情报。 2. 多媒体数据 ▪ 图片:如JPEG、PNG、GIF等格式的图片。企业可以通过图像识别技术从中提取有价值的信息,如产品缺陷检测、面部识别等。 ▪ 视频:包括MP4、AVI、MOV等格式的视频文件。视频分析技术可以用于监控、市场营销、用户行为分析等。 ▪ 音频:如WAV、MP3等格式的音频文件。通过语音识别技术,企业可以将音频转换为文本进行进一步分析,应用于客服记录、电话会议记录等。 3. 传感器数据 ▪ 物联网(IoT)数据:来自各种传感器和智能设备的数据,如温度传感器、湿度传感器、运动检测器等。这些数据可以用于智能家居、工业自动化、环境监测等领域。 ▪ GPS数据:包括位置、速度、时间戳等信息,广泛应用于物流、交通管理、地理位置服务等。 4. 日志数据 ▪ 服务器日志:记录服务器运行状态、用户访问记录、错误信息等。通过分析服务器日志,企业可以优化系统性能、提升安全性。 ▪ 应用日志:记录应用程序的运行情况、用户操作等。企业可以通过分析这些日志了解用户行为、改进产品功能。 5. 其他类型的数据 ▪ 聊天记录:来自即时通讯工具(如微信、Slack、WhatsApp等)的聊天记录。这些数据能够帮助企业了解内部沟通情况、客户服务质量等。 ▪ 网页数据:包括HTML内容、网页元素、用户交互记录等。通过抓取和分析网页数据,企业可以进行竞争对手分析、市场调研等。 ▪ 生物数据:如DNA序列、医学影像、健康监测数据等。特别在医疗领域,这些数据对于疾病研究、个性化医疗具有重要意义。 非结构化数据与传统结构化数据的对比:

三、非结构化数据的挑战
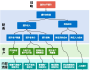
非结构化数据管理面临存储、检索、处理、集成、质量管理等多方面挑战,如下图所示:

具体挑战如下表所示:

四、非结构化数据存储技术
非结构化数据的存储是大数据管理的重要环节,针对非结构化数据的特点,主要有以下几种存储技术和系统:

1、分布式文件系统(Distributed File System) ▪ Hadoop HDFS\:Hadoop生态系统的核心存储组件,提供高吞吐量的数据访问 ▪ Google GFS\:Google公司开发的分布式文件系统,Hadoop HDFS的设计原型 ▪ Ceph:一种高性能、高可靠的统一分布式存储系统 ▪ FastDFS:轻量级分布式文件系统,适用于中小规模的文件存储场景 分布式文件系统通过将大文件分块存储在多个服务器上,实现了海量非结构化数据的高效存储和访问。HDFS等系统还提供了数据备份和容错机制,保障了存储的可靠性。 2、NoSQL数据库(Not Only SQL Database) ▪ 键值数据库:如Redis、Memcached,适合存储简单的键值对数据 ▪ 文档数据库:如MongoDB、CouchDB,适合存储半结构化的JSON/XML文档 ▪ 列族数据库:如Cassandra、HBase,适合存储超大规模的结构化和半结构化数据 ▪ 图数据库:如Neo4j、JanusGraph,适合存储复杂的关系网络数据 NoSQL数据库摒弃了传统关系型数据库的事务ACID特性,从而在性能、可扩展性、灵活性等方面取得了突破。不同种类的NoSQL数据库适用于不同类型的非结构化数据存储。 3、对象存储(Object Storage) ▪ Amazon S3:亚马逊公司推出的云存储服务,提供了高可扩展性和持久性 ▪ OpenStack Swift:开源的分布式对象存储系统,兼容S3 API ▪ Ceph RADOS\:Ceph系统的对象存储组件,提供了类似S3的对象存储接口 对象存储将非结构化数据以"对象"的形式存储,每个对象包含数据本体和元数据属性。相比块存储和文件存储,对象存储在扩展性、访问效率、数据持久性等方面具有优势。 4、大数据综合存储系统 ▪ Apache Hadoop\:Hadoop生态系统包含了HDFS、HBase、Hive等多个数据存储组件 ▪ Apache Spark\:Spark生态系统包含了HDFS、Alluxio、Kudu等存储方案 ▪ Snowflake:基于云计算的数据仓库解决方案,提供了结构化和半结构化数据的统一存储 综合存储平台将不同种类的数据存储系统整合到统一的架构中,平衡了非结构化数据存储的性能、容量和成本。 5、云存储服务(Cloud Storage Service) ▪ 阿里云OSS:阿里云提供的海量、安全、低成本、高可靠的云存储服务 ▪ 腾讯云COS:腾讯云提供的分布式存储服务,支持多种数据格式 ▪ 华为云OBS:华为云提供的对象存储服务,提供高扩展性和数据持久性保障 云存储服务将非结构化数据存储任务托管给云服务提供商,使企业能够以更低的成本、更高的可靠性管理海量非结构化数据,是大数据时代的重要技术趋势。 非结构化数据存储是一个复杂的系统工程,需要综合考虑数据量、数据类型、访问模式、处理需求等因素,选择和搭建合适的存储方案。同时,不同的存储技术之间也可以互补整合,形成多层次、多类型的存储架构,从而在性能、容量、成本等方面达到最优平衡。
五、非结构化数据索引与检索
非结构化数据的索引和检索是大数据管理的核心问题之一。由于非结构化数据种类多样、数据量巨大,传统的数据库索引技术难以直接应用。针对不同类型的非结构化数据,主要有以下索引和检索技术:

1、全文检索(Full-text Search) ▪ 倒排索引:将文档内容切分为词条,记录每个词条在文档中的位置信息,形成"词条-文档"的映射关系 ▪ 正排索引:按照文档的顺序,记录每个文档包含的词条信息,形成"文档-词条"的映射关系 ▪ 搜索引擎:如Elasticsearch、Solr、Lucene等,基于倒排索引实现高效的全文检索功能 全文检索主要针对非结构化的文本数据,如办公文档、邮件、网页等。通过倒排索引,可以快速找到包含指定关键词的文档,实现海量文本数据的实时搜索。 例:在搜索引擎中查询"大数据存储技术",搜索引擎会返回所有包含"大数据"、"存储"、"技术"的网页,并按照相关性排序。这就是基于倒排索引实现的全文检索。 2、语义索引(Semantic Indexing) ▪ 主题模型:如LDA(Latent Dirichlet Allocation),通过无监督学习方法,从文本语料中提取潜在主题,实现文本的主题索引 ▪ 关键词提取:通过TF-IDF(Term Frequency-Inverse Document Frequency)等算法,从文本中提取关键词,形成关键词索引 ▪ 命名实体识别:利用自然语言处理技术,从文本中识别出人名、地名、机构名等命名实体,形成实体索引 语义索引在全文检索的基础上,引入了语义分析技术,试图理解文本的内在含义,提取更高层次的索引信息。语义索引可以支持更加智能、更加精准的语义检索。 例:在一个新闻网站上,文章的主题和关键词被自动提取出来,当用户搜索"人工智能",系统不仅返回包含"人工智能"的文章,还会返回与"机器学习"、"深度学习"等相关主题的文章。这种基于主题和关键词的搜索就是语义索引的应用。 3、多媒体索引(Multimedia Indexing) ▪ 图像索引:如SIFT(Scale-Invariant Feature Transform)特征提取,通过提取图像的关键特征,构建图像特征索引 ▪ 音频索引:通过语音识别技术,将音频转换为文本,再利用文本索引技术实现音频内容的检索 ▪ 视频索引:在音频索引的基础上,通过视频帧分析、场景识别等技术,提取视频的关键帧和场景,形成视频内容索引 多媒体索引面向图像、音频、视频等非文本数据,通过信号处理、模式识别等技术,提取多媒体数据的内容特征,实现基于内容的多媒体检索。 例:在一个图片网站上,当你上传一张风景照片时,系统自动识别出照片中的山川、大海等元素,并为其打上标签。之后,当其他用户搜索"大海"时,你的照片就会出现在搜索结果中。这就是利用图像索引实现的图片内容检索。 4、时空索引(Spatio-temporal Indexing) ▪ 空间索引:如R树、Quad树等,通过树形结构划分和组织空间数据,加速空间范围查询和最近邻查询 ▪ 时间索引:通过时间戳或时间区间,对时序数据进行索引,支持基于时间的数据检索和聚合分析 ▪ 时空索引:如 R*树、Octree等,综合考虑数据的时间和空间属性,实现时空数据的高效索引和查询 时空索引主要针对具有时间和空间属性的数据,如轨迹数据、传感器数据、地理信息数据等。通过时空索引,可以支持复杂的时空查询和数据分析。 例:在导航应用中,当你搜索"附近的餐馆"时,系统会根据你的当前位置,快速找到周围的餐馆并显示在地图上。这个过程用到了空间索引,通过经纬度等空间信息快速定位附近的POI(Point of Interest)。 5、图数据索引(Graph Data Indexing) ▪ 图遍历索引:通过预先计算和存储图的遍历结果(如最短路径、连通性),加速图数据的查询和分析 ▪ 图模式索引:通过图特征提取和图模式匹配,实现图数据的相似性搜索和模式查询 ▪ 图嵌入索引:利用图嵌入(Graph Embedding)技术,将图数据映射到低维向量空间,实现高效的图数据索引和检索 图数据索引面向复杂的关系网络数据,如社交网络、知识图谱、推荐系统等。图数据索引通过图论算法和机器学习方法,挖掘图数据的结构和语义信息,支持高效的图数据查询和分析。 例:在社交网络中,当你搜索某个人的名字时,系统会根据人与人之间的关系(如好友、同学、同事等),快速找到与你searched人相关的其他用户。这个过程利用了图数据索引,通过图的遍历和查询快速发现关联的人和信息。
六、非结构化数据的分析与处理
非结构化数据的分析和处理是从海量、杂乱的非结构化数据中提取有价值信息和知识的过程。针对不同类型的非结构化数据,主要有以下分析和处理技术:

1、文本分析(Text Analytics) ▪ 自然语言处理(NLP):通过词法分析、句法分析、语义分析等技术,理解文本的语言结构和含义 ▪ 文本挖掘(Text Mining):从大规模文本数据中发现有价值的模式、规律和知识 ▪ 情感分析(Sentiment Analysis):识别和提取文本中表达的情感、观点和态度 案例:通过对社交媒体上的用户评论进行文本分析,发现用户对某个产品的看法,及时改进产品策略。 2、图像分析(Image Analytics) ▪ 计算机视觉(Computer Vision):通过图像处理、模式识别等技术,使计算机具备"看"的能力 ▪ 图像分类(Image Classification):将图像划分到预定义的类别,如猫、狗、风景等 ▪ 目标检测(Object Detection):在图像中定位和识别出感兴趣的目标物体 案例:利用图像分析技术,对医学影像(如X光片、CT)进行自动诊断,辅助医生做出更准确的判断。 3、音频分析(Audio Analytics) ▪ 语音识别(Speech Recognition):将语音信号转换为文本,实现人机语音交互 ▪ 说话人识别(Speaker Recognition):根据语音的特征,识别说话人的身份 ▪ 音频分类(Audio Classification):将音频划分到预定义的类别,如音乐、噪音、人声等 案例:智能客服系统通过语音识别和语义理解,自动回答客户的常见问题,提高客服效率。 4、视频分析(Video Analytics) ▪ 视频分割(Video Segmentation):将视频划分为语义上有意义的片段,如镜头、场景等 ▪ 行为识别(Action Recognition):从视频中识别出人或物体的行为和动作 ▪ 视频摘要(Video Summarization):自动提取视频的关键片段,生成视频摘要或预览 案例:通过对监控视频进行实时分析,及时发现异常行为和潜在威胁,保障公共安全。 5、社交网络分析(Social Network Analytics) ▪ 社区发现(Community Detection):在社交网络中识别紧密联系的用户群体 ▪ 影响力分析(Influence Analysis):发现社交网络中的关键意见领袖和传播路径 ▪ 链接预测(Link Prediction):预测社交网络中潜在的关系链接 案例:通过分析用户在社交网络上的互动行为,发现潜在的营销机会和目标人群。 6、时空数据分析(Spatio-temporal Data Analytics) ▪ 轨迹挖掘(Trajectory Mining):从大量轨迹数据中发现有意义的移动模式 ▪ 异常检测(Anomaly Detection):发现时空数据中异常的事件或行为 ▪ 热点分析(Hotspot Analysis):识别时空数据中的高密度区域或聚集模式 案例:通过分析城市交通轨迹数据,优化交通规划和管理,缓解交通拥堵问题。 非结构化数据的分析和处理是一个复杂的过程,通常需要结合多种技术和方法,如机器学习、数据挖掘、可视化等。同时,非结构化数据分析也是一个探索性的过程,需要分析者具有敏锐的洞察力和创新思维,能够从数据中发现有价值的信息和见解。
七、非结构化数据管理平台
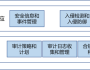
非结构化数据管理平台是一种集成的技术栈,能够处理多种形式的非结构化数据(如文本、图像、视频、音频、传感器数据等),从数据收集、存储、处理、分析、可视化到检索,提供端到端的数据管理解决方案。主要功能如下:

1. 平台架构 (1)数据采集层 ▪ ETL工具:使用Flume、Kafka等工具,实时采集服务器日志、社交媒体数据等非结构化数据。 ▪ 爬虫工具:用于从网页自动抓取数据。 ▪ API连接:通过API接口从社交媒体、传感器网络等数据源收集数据。 (2)数据存储层 ▪ 分布式文件系统:如Hadoop HDFS、Google GFS,支持大规模文件存储。 ▪ 对象存储:如Amazon S3、OpenStack Swift,适合存储多媒体数据。 ▪ NoSQL数据库:如MongoDB、Cassandra,用于存储灵活的文档数据。 ▪ 数据湖:综合使用上述技术,构建企业级数据湖,存储各种类型的非结构化数据。 (3)数据处理层 ▪ 数据清洗和转换:提供分布式计算框架,如MapReduce、Spark、Flink等,对非结构化数据进行并行处理。 ▪ 特征提取:使用NLP、图像处理、音频处理等技术从数据中提取有用特征。 ▪ 数据索引:建立高效的数据索引,支持快速检索。 (4)数据分析层 ▪ 机器学习平台:如TensorFlow、PyTorch,用于训练和部署机器学习模型。 ▪ 数据可视化:如Tableau,提供丰富的数据可视化组件,如仪表盘、报表、图表等,方便用户探索和理解数据。 ▪ 图像和视频分析:使用OpenCV、Deep Learning框架进行多媒体数据分析。 (5)数据搜索层 ▪ 全文检索:集成搜索引擎,如Elasticsearch、Solr等,实现非结构化数据的全文检索和查询 ▪ 语义搜索:利用知识图谱和本体技术,实现基于语义的非结构化数据查询和推荐 ▪ 多模态检索:支持文本、图像、音视频等多种非结构化数据的综合检索 (6)数据安全层 ▪ 身份验证与授权:使用Kerberos、OAuth等技术确保数据访问安全。 ▪ 数据加密:采用AES、RSA等加密算法保护数据安全。 ▪ 审计和合规:提供数据审计日志和合规性检查功能,确保数据管理符合相关法规。 2、主要平台介绍 一些常见的非结构化数据管理平台包括: (1)国际平台: ▪ Hadoop生态系统:包括HDFS、HBase、Hive、Spark等组件,提供非结构化数据的存储、处理和分析能力 ▪ Cloudera、Hortonworks、MapR:基于Hadoop的商业发行版,提供更加易用、稳定、安全的大数据平台 ▪ AWS、Azure、GCP:云服务提供商提供的大数据平台,如AWS EMR、Azure HDInsight、Google Cloud Dataproc等 ▪ MongoDB Atlas、Datastax、Couchbase:基于NoSQL数据库的非结构化数据管理平台 ▪ Snowflake、Databricks:基于云原生架构的大数据平台,提供数据仓库、数据湖和数据科学平台功能 (2)国内平台: ▪ 阿里巴巴大数据平台:包括飞天(MaxCompute)、E-MapReduce、DataLake Analytics等,提供一站式大数据开发、管理和分析平台 ▪ 腾讯大数据平台:包括腾讯云Sparkling、Oceanus、Elasticsearch等,提供实时计算、离线处理、搜索分析等大数据服务 ▪ 华为大数据平台FusionInsight:包括存储、计算、分析、可视化等全栈能力,支持多种大数据组件和工具 ▪ 百度AI大数据平台:融合ABC(AI、Big Data、Cloud)能力,提供一站式大数据和人工智能解决方案 ▪ 平安金融壹账通:利用大数据、人工智能等技术,为金融机构提供智能化、数字化的非结构化数据管理方案 非结构化数据管理平台的选择需要考虑组织的数据规模、业务需求、技术能力、预算等因素。一个好的非结构化数据管理平台应该具备高可扩展性、高性能、高可用性、安全可靠等特点,能够帮助组织快速构建和部署大数据应用,实现数据驱动的业务创新和价值释放。
八、未来展望
非结构化数据管理在未来将迎来巨大的发展机遇和变革。以下是对非结构化数据管理未来的五点展望:

1、人工智能驱动的智能化管理 ▪ 自然语言处理:利用NLP技术,实现非结构化数据的自动分类、主题提取、情感分析等,提高数据管理的智能化水平 ▪ 计算机视觉:应用计算机视觉算法,自动识别和标注图像、视频等非结构化数据,实现数据的自动元数据提取和内容理解 ▪ 知识图谱:构建领域知识图谱,实现非结构化数据的语义关联和推理,支持更加智能的数据检索和分析 ▪ 强化学习:利用强化学习技术,优化非结构化数据管理的策略和流程,实现数据管理的自适应和自优化 2、云原生架构下的敏捷数据管理 ▪ 容器化部署:使用Docker等容器技术,实现非结构化数据管理组件的快速部署、弹性伸缩和高可用性 ▪ 微服务架构:将非结构化数据管理平台拆分为多个松耦合的微服务,提高系统的灵活性、可扩展性和容错性 ▪ 无服务器计算:利用Serverless计算模型,实现非结构化数据处理的自动化和按需伸缩,降低数据管理的运维成本 ▪ 多云环境:支持非结构化数据在多个云平台之间的无缝迁移和同步,实现数据管理的云端协同与互操作 3、数据隐私与安全的加强 ▪ 数据加密:采用同态加密、多方安全计算等隐私保护技术,实现非结构化数据在处理和分析过程中的隐私保护 ▪ 访问控制:基于属性的访问控制(ABAC)、基于角色的访问控制(RBAC)等细粒度的数据访问控制机制,保障非结构化数据的安全性 ▪ 数据脱敏:通过数据脱敏技术,如数据混淆、数据匿名化等,保护非结构化数据中的敏感信息,避免隐私泄露 ▪ 区块链:利用区块链技术,实现非结构化数据的可信存证、溯源和审计,提高数据管理的可信度和不可篡改性 4、边缘计算环境下的分布式数据管理 ▪ 边云协同:支持非结构化数据在边缘设备和云平台之间的高效传输和同步,实现数据的就近处理和分析 ▪ 数据预处理:在边缘设备上对非结构化数据进行预处理、过滤和压缩,减少数据传输的带宽压力和延迟 ▪ 联邦学习:运用联邦学习技术,在不共享原始数据的情况下,实现多个边缘节点之间的协同学习和模型优化 ▪ 数据治理:建立适用于边缘环境的数据治理框架,解决边缘数据的所有权、隐私保护、质量管理等问题 5、数据网格(Data Mesh)理念的引入 ▪ 域驱动数据所有权:按照业务域来划分数据的所有权和管理职责,实现数据治理的分散化和自治化 ▪ 数据即产品:将数据视为一种产品,有明确的SLA、API和文档,供其他域和团队使用和集成 ▪ 自助式数据基础设施:提供标准化、自动化的数据基础设施,使各个域能够自助地管理和服务他们的数据 ▪ 联合数据治理:在中央数据治理团队的协调下,实现跨域数据的标准制定、质量管理和安全合规 非结构化数据管理正朝着智能化、敏捷化、安全化的方向不断发展。未来,非结构化数据管理将与人工智能、云计算、边缘计算、区块链等新兴技术深度融合,形成更加智能、高效、安全、去中心化的数据管理新模式。
(以上内容摘录自网络,如有侵权请联系删除) |